As companies seek to connect or integrate their content marketing technologies, they’re turning to solutions such as Digital Asset Management (DAM) and Content Hub platforms to help manage their marketing content, making it easier to find, edit, and publish. While these technologies are evolving into powerful tools, they don’t hold all the answers to untangling content chaos. The truth is: Your systems are only as good as your planning and preparation – and, ultimately, your configuration.
When working with digital assets a few things you should always consider are:
- Will you be able to find your content later?
- Will you be able to refer, relate, or link back to it when working on the next content piece or updating the current one?
- Will your teams be collaborating with others – either inside or outside of your organization?
These considerations present a twofold problem, one for the back-end systems used to manage/collaborate on content (content hub/DAM), and the other for the system’s users, many of whom are accustomed to creating desktop or online folder to suit their own needs -- but not necessarily making their work easy for others to find and use.
TAGGING SOLVES ONLY PART OF THE PROBLEM
Most modern systems are built with back-end searchability as a core capability, and the user experience is driven by a familiar search interface, with opportunities to tag content to help make it searchable.
Does this mean the systems themselves are able to address the concerns listed above? No, not quite. Systems are getting smarter; some even employ AI either to suggest tags or auto-tag assets. But, as smart as it is, automatic tagging may not conform to your brand’s needs because, to a degree, it’s user-driven. Consider: Will your teams remember all the asset names and tags 6 months after they upload the assets? Probably not.
Why? Because, generally speaking, not enough attention is paid to creating a standardized structure for classifying and categorizing content. The results?
Overuse of or abuse of taxonomy. Taxonomy doesn’t have to be complex; it just needs to be effective. If you make it too granular, with categories that are too deep, your content will be impossible to find or your content hub/DAM will spin as it processes your search. If, on the other hand, you define your taxonomy too loosely and broadly, it will be equally ineffective. Additionally, if your taxonomy is too deep, your content authors will find it difficult to use and will likely abandon it. There’s a balance you need to achieve if your taxonomy is to be effective and adopted by your creative teams.
Incomplete or missing metadata. All of your content and visual assets should have metadata describing what they are, who created/updated them, dates they were created/updated, and so on -- however your content governance plan defines metadata. That includes any legacy content you plan to migrate from other systems or archives. If your metadata is incomplete, missing, or inconsistent, you’ll have problems. And if you intend to publish the content to the web, metadata helps with SEO and accessibility (501 compliance).
Improper, inadequate, or non-existing tagging strategy. A good way to explain this is by using WordPress tag clouds as an example. Writers can tag their blog posts using a free-text field, often resulting in a proliferation of tags that all mean the same thing, with slightly different wording. And that leads to...
Using field types that allow misspellings or synonyms to creep in. There are uses for free-text fields that allow users to generate their own tags. Your content organization is not one of them. Tagging should be accomplished via drop-down menus or other means of selection so that your content categorization structure remains clear, clean, and effective.
Clearly, much of the solution rests with planning for and standardizing how content is categorized with a solid, logical taxonomy structure. Yet, time and again, we work with companies that find their content tipping back into chaos, even after investing in best-of-breed systems, simply because they don’t adequately plan and fully optimize their content taxonomies.
DIGITAL ASSETS, TAXONOMY, AND METADATA - WHEN FILES AREN'T YOUR ONLY ASSET
Always remember: A digital asset or content element is not just the physical file, but, more importantly, it’s the metadata defining the asset or content. Taxonomy and metadata are the mechanisms that not only drive search (internal as well as SEO) but also contribute to versioning and other important aspects of content management. So, it’s important that assets are classified into taxonomies and are assigned intuitive, real-use metadata.
So, you might ask, “what are these taxonomies and metadata you speak of, and how do they relate to my content and digital assets?” In a nutshell:
Taxonomy, most simply defined, is a system for labeling and organizing data into categories, based on their similarities.
Metadata goes a little deeper and provides context or additional information for the data organized into taxonomies – size, color, shape, or other attributes, for example.
Notice that my definition of the word taxonomy includes the word system. Systems require not only modeling and mapping but also a level of agreement if they’re to behave (and be adopted) consistently. Ad hoc categories are anything but systematic. (In fact, creating taxonomies and metadata is an excellent task for the content governance board I talk about in another article.) Your taxonomies and metadata should be created intentionally and carefully, with as much collaboration and buy-in as you can get across users and business units or brands.
So you know you need them, but where do you start? Easy: Data modeling.
USING DATA MODELING TO CATEGORIZE AND TAG CONTENT COLLABORATIVELY
Our recommendation for a successful content hub or DAM implementation is to set up workshops (perhaps led by that content governance board!) with the primary objective of defining a data model for the assets. In other words, identify the metadata and categories, and define the fields in your DAM, CMS, and other systems you’ll use to store this information. Your data model might start out as something as simple as post-it notes (think: card-sorting exercise) or as complex as a spreadsheet.
For example an image asset could have the following properties:
- Name (metadata)
- Creation date (metadata)
- Update date (metadata)
- Description (metadata)
- Title (metadata)
- Filename (metadata)
- Tags (metadata)
- Type (metadata)
- Category (taxonomy)
Once you’ve defined your data, you can create a model that will work for your organization.
I like the modeling used in this post about taxonomy guidelines from Market Land’s Shari Thurow because it illustrates multiple ways of approaching how to categorize your assets, from simple to hierarchical to faceted, depending on the complexity and needs of your business.

In addition to system configuration and user searches, taxonomy can be used for hierarchical classification, maybe even used for navigation like the following illustration of a hierarchy taxonomy, also from Thurow’s post:
Example of a “facet” taxonomy model, copied from marketingland.com
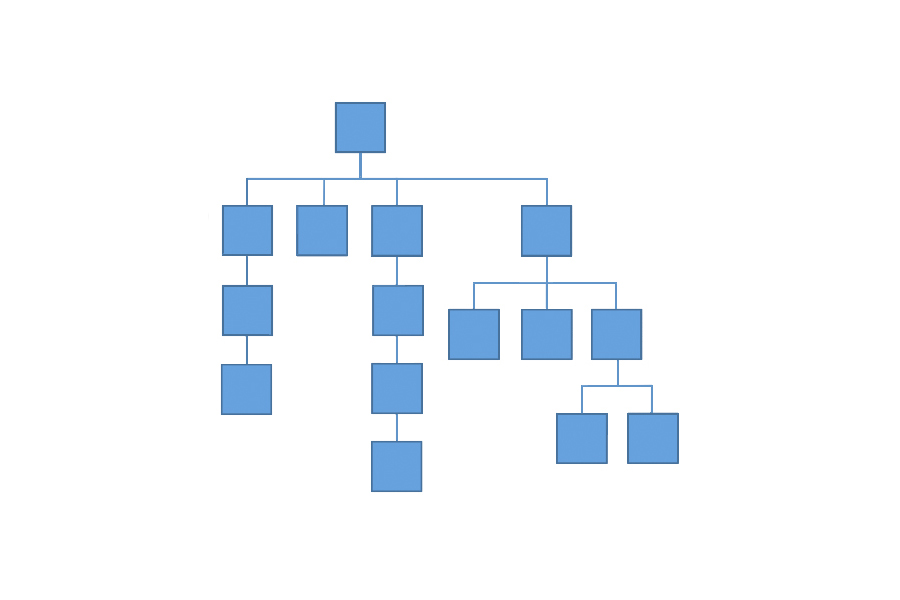
Example of a “hierarchy” taxonomy model, copied from marketingland.com
Also remember that this is the same data that will be pushed out to your marketing channels – social, website, store etc. A well-structured taxonomy with consistent metadata across systems will make content, page, site, and channel enhancement and management easier.
DATA MODELING IS AN ITERATIVE PROCESS
We typically go through an iterative process for data modeling exercises, as it is important to get your content hub/DAM users to test the system and provide feedback/suggest changes. Another important goal of iterative modeling is to identify the field types needed, such as option lists and free-text fields, for each content type. By doing so we can reduce the chances of misspellings and unapproved term usage, as well as enhance the handling of translations for multinational/multilingual brands.
The benefits of conducting a data modeling exercise are that every datapoint we collect can then be used to define search facets. (Think: “faceted search,” or the details that drill down to find exactly what you’re looking for.) Facets can be used for defining permissions; properties on the asset can be used for querying and also to expose more details on how an asset is being used. Governance teams walking through such an exercise, step by step, are able to create an agreed-upon structure and a system for using it.
And that is the key to a successfully optimized taxonomy: It reflects and supports how your teams and end users find and use the content and assets they need.
Having trouble keeping your content under control? Learn more about Sitecore Content Hub.

NIKET ASHESH
Partner